Unified Namespaces
In this section of the documentation we discuss what a unified namespace (UNS) is, why you need a UNS, the scope of unified namespaces, why there is not a single unified namespace and how to use FogLAMP Manage to define a unified namespace for asset naming for all data pipelines across a fleet of FogLAMP instances that implement those data pipelines.
What is a UNS
A unified namespace is very simply a way to address the data in your system in a common way that facilitates the use of that data. It creates a contract by which data is identified between the producer and the consumer of the data. It is possible to have very limited contracts between producers and consumers, resulting in local, limited namespaces. However, restricting namespace definitions to between single producers and consumers, makes it difficult to access data in a portable fashion. It also means that many such contracts are needed between the individual consumers and producers, resulting in poor portability of the applications that consume the data. Sharing data between consumers becomes more difficult and the maintenance of all these various contracts becomes more resource consuming and difficult to manage.
UNS Scope
It is important to recognise that a unified namespace is not universal. Different organisations, or different roles within the same organisation, will have different requirements on a namespace and will view data in different ways. It is important to consider the scope of any unified namespace and also how those namespaces may be translated into different namespaces for different consumers.
There are numerous real world examples, outside of the industrial arena, of the use of different unified namespaces.
Location is an obvious case when multiple unified namespaces are used the real world. The many ways location can be identified; for example you may use longitude and latitude to identify the location in the world. This uniquely names every location within the world, however we do not send a letter or parcel to a longitude and latitude. Postal addresses are used in this case. The postal address is another, equally valid unified namespace for defining location. The difference is who is consuming the location data, you would not expect the postal service or a courier to accept longitude and latitude, equally a pilot would not navigate to the postal address of an airport. Although the airport clearly has both a postal address and a longitude and latitude. It is the consumer of the data that defines the namespace to use.
In the industrial setting there are equally cases where multiple namespaces may be needed. As an example, the maintenance department and the product quality department are consumers of the data produced by the plant involved in production. However one is interested in the data about the item of plant itself, whilst the other is more concerned with the product being produced. One will require a namespace that identifies the plant whilst the other might be interested in a product code and batch or serial number.
Another example is where data is shared between different organisations. It is extremely unlikely that two organisations will have the same namespace, each will have its own namespace. Also the organisations are unlikely to wish to share all of the data in their namespace with an outside party. Therefore some mapping of the internal namespace to the external, shareable namespace is to be required. This mapping may take place at both the producer, limiting and reogranising the data that is shared, and by the consumer, mapping the publicly agreed namespace to one used by the consumer. Potentially the consumer may augment the data internally, adding to the namespace.
Where to apply a Unified Namespace
Data is rarely ingested into a collection framework already in a unified namespace, with the possible exception of when that data is originating from an application rather than a plant data source. The data therefore has, at some point, to be assigned a unified name in order to fit within the namespace requirements of the consumer.
There is an argument for applying the unified namespace at a centralised location, such as in the historian or if a common location exists within the transmission path of the data, between the producer and the consumers of that data. However there are some factors that should be taken into account
The choice of location for implementing your UNS limits consumers of the data to upstream of that point. A consumer in the data pipeline before the namespace is unified results in the consumer requiring a private contract with the producer of the data.
Dumping all of the data, in a central location and then applying a process to unify the namespace centralises the process. It requires the data in this location be identifiable. For example the source of that data, and that rules can be written to cope with all of the different data sources at this one location. Each new data source requires new rules to be added to the central location, increasing the complexity of those rules.
Applying the namespace as part of the transport of the data in attractive, but only works if:
All the producers send data via that same mechanism.
The data contains sufficient information to identify data to the transport.
The transport layer has a mechanism to translate the internal names of each producer to the unified namespace.
FogLAMP Suite & Unified Namespaces
FogLAMP Suite provides mechanisms that allow namespaces to be applied at or very close to the point of collection of data. It also provides a way to generate names using metadata regarding the collection process or the data itself in order to automate the creation of the unified names for a data item or set of data items.
FogLAMP Suite also provides mechanisms to enforce the naming, either through use of templates to limit the freedom of naming when creating data ingestion pipelines or via processing filters that will detect and act upon data that does not fit the defined namespace.
Translation between namespaces is handled in FogLAMP Manage through the use of “hint” filters. The hint filters map the source namespace into the consumer’s namespace. They may also perform other mapping operations outside of the scope of namespace manipulation.
Metadata
In FogLAMP Manage, Metadata may be added to any of the elements in the pipeline. Metadata is then used at deployment time to expand macros used for configuration. The metadata takes the form of name/value pairs. Metadata can be added to the templates created for entities within FogLAMP Manage. This allows the template creator to force the user of the template to enter a value for the metadata item.
|
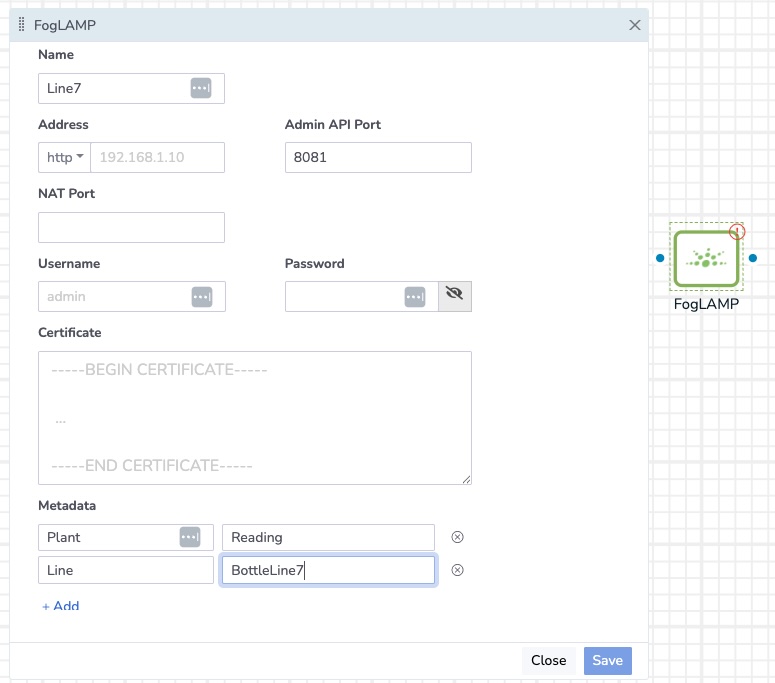
The metadata is only used for deployment time expansion of macros and is not included in any readings generated by the pipeline.
There are a number of predefined metadata items that can be used in macro expansions
Item |
Description |
|---|---|
$Address$ |
The IP address of the entity. |
$SrcAddress$ |
The IP address of the source of the connection. Only valid on connection elements. |
$DstAddress$ |
The IP address of the destination of the connection. Only valid on connection elements. |
$Name$ |
The name of the entity. |
$SrcName$ |
The name of the source entity in a connection. |
$DstName$ |
The name of the destination entity in a connection. |
$Src(name)$ |
We substitute the value of the property name from the source of the connection. Valid only for connection templates. E.g. if you wish to use the Map property from the source of a connection you add the macro $Src(Map)$. |
$Dst(name)$ |
We substitute the value of the property name from the destination of the connection. Valid only for connection templates. |
Macros
FogLAMP Suite provides macros as a mechanism to define a pattern for a value and create that value using metadata or data read from the source. This macro expansion can be applied to the naming of the data, via the asset code associated with a reading. Two levels of macro expansion occur within FogLAMP Suite;
Deployment Time Expansion
In deployment time expansion, the macro is fully expanded at the time FogLAMP Manage deploys the data pipelines to the individual FogLAMP instances. The values needed to expand the macros come from fixed metadata added to the elements of the data pipeline within FogLAMP Manage and do not change at execution time.
The expansion process of a macro will look at all the elements in the pipeline in order to find the metadata that is needed to expand the macro.
Run time Expansion
Run time expansion occurs when a macro will use one or more components of the data read in order to fully expand the macro. This occurs within the FogLAMP data pipeline for each reading as it progresses through the pipeline. This allows data that has been read from the source to be included in the macro expansion.
Macros may be defined either within the template of the element or entered in by the user as a value of a particular property. If enforcing a namespace convention, then it is best to add the macro into the template and make the value immutable. The immutable property means that the macro itself can not be changed, but the expansion is still done. Therefore the individual elements in the macro are controlled b the metadata entered in the elements in FogLAMP Manage, but the structure of the resulting name is fixed.
As an example, assume we have a very simple UNS we want to enforce, it has the asset name, the line the asset is part of and the plant name. We would define a macro such as below to express this UNS format we require.
$AssetName$-$Line$-$Plant$
This asset name macro is set in the Asset Name property of the PLC that is the data source for reading our data, in this example we are using a pump.
|
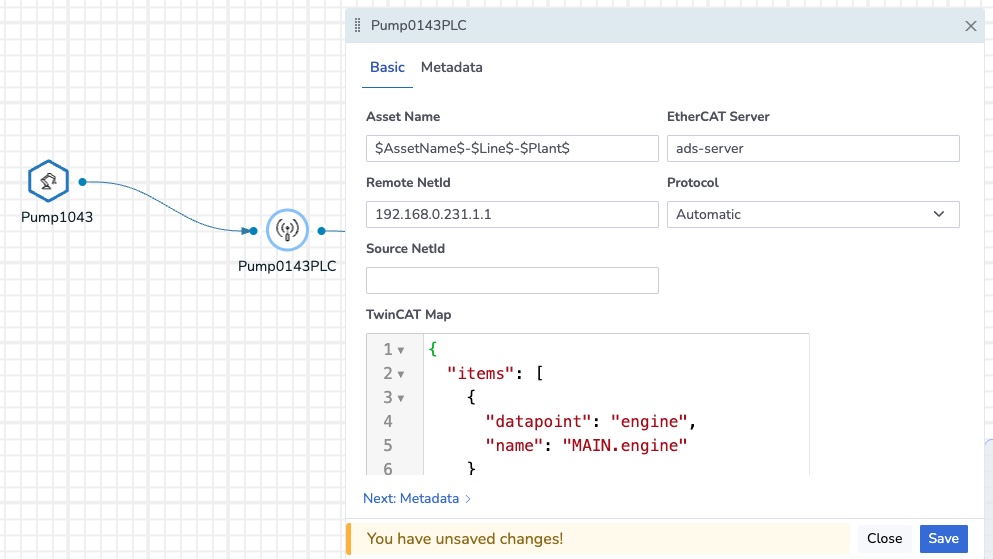
We will further assume each production line has a dedicated FogLAMP instance used solely to gather data regarding that line.
In the asset element in the pipeline we will define a metadata item called AssetName, in the FogLAMP instance we will define two metadata items; Line and Plant. Since this data is defined in the metadata of the FogLAMP rather than the asset, it means it is only entered once per FogLAMP. It also means that if the item is moved to a different line then the act of disconnecting it from one FogLAMP and connecting it to another will automatically update the UNS name of the asset.
|
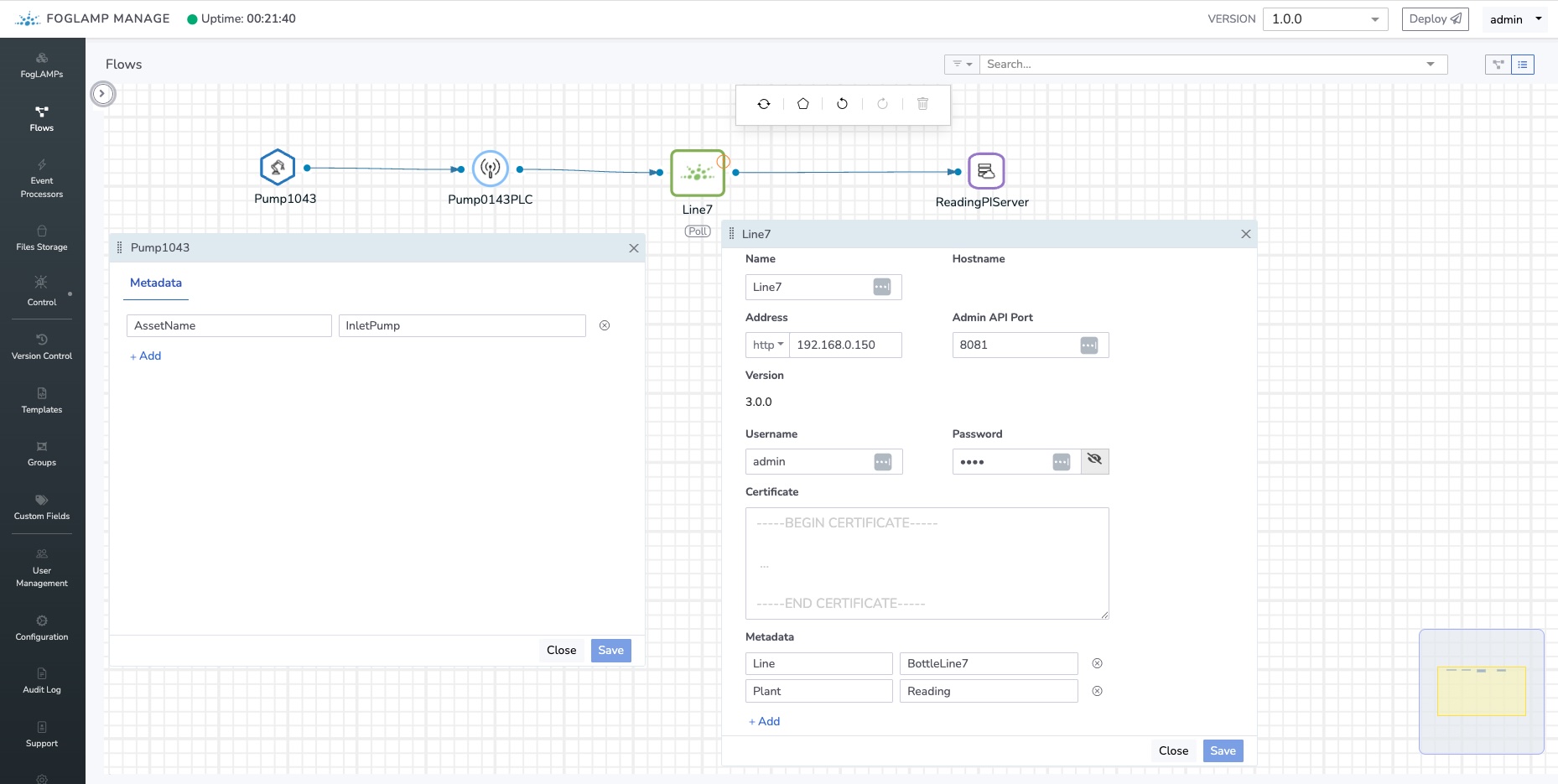
Since all the items required to expand the macro are defined as metadata in the FogLAMP Manage elements, the macro can be fully expanded at deployment time. The resultant expansion will therefore become a simple string in the configuration sent to FogLAMP.
A more complex example, where we wish to send data to a destination regarding the particular items that are being manufactured would use a run time expanded macro. Let us assume we have a means to have a serial no in the asset reading for our item of interest and we are sending to an OMF destination. We want to map onto an Asset Framework namespace in the OMF based destination that is serial number based. We do this by defining an AFLocation hint in the OMFHint filter that sends data to this destination. The AF Hierarchy we want to create is defined by the macro
/$SerialNo$/$AssetName$
As above, the AssetName is taken from the metadata defined in the asset and is expanded at deployment time. However the SerialNo is not available at deployment time, as this is information that is dynamically read or created in the ingest pipeline that is reading the data. Therefore the OMF Hint filter will receive a partly expanded macro. At run time the value of the SerialNo datapoint will be taken and substituted into the AF Location hint used by the OMF Hint filter.
Since this is being done only in the pipeline that delivers data via this OMF integration, only this integration will use this namespace. The other interactions, i.e. consumers of the data, will see the default namespace or can have a custom mapped namespace for that consumer of the data.
In this example we used the SerialNo datapoint to expand the macro, assuming this was added at some point earlier in the data pipeline. FogLAMP provides a number of filters that can be used to create and populate string based data in a pipeline. These can be used to create the datapoints needed in macro expansion by extracting sub-strings, mapping numeric values or applying substitutions to other datapoints in the data stream. This allows values that would otherwise not be readily readable to be created and used in macros expansion later in the pipeline.